
Benchmarking clustering algorithms through wisdom of crowds
Ever wonder why every cytometry benchmarking study recommends a different algorithm? It’s because different performance metrics interact with different datasets to give biased results towards any given algorithm. Metrics are not impartial, they emphasise different features of a dataset and an algorithm. So how are investigators to choose the most appropriate algorithm?
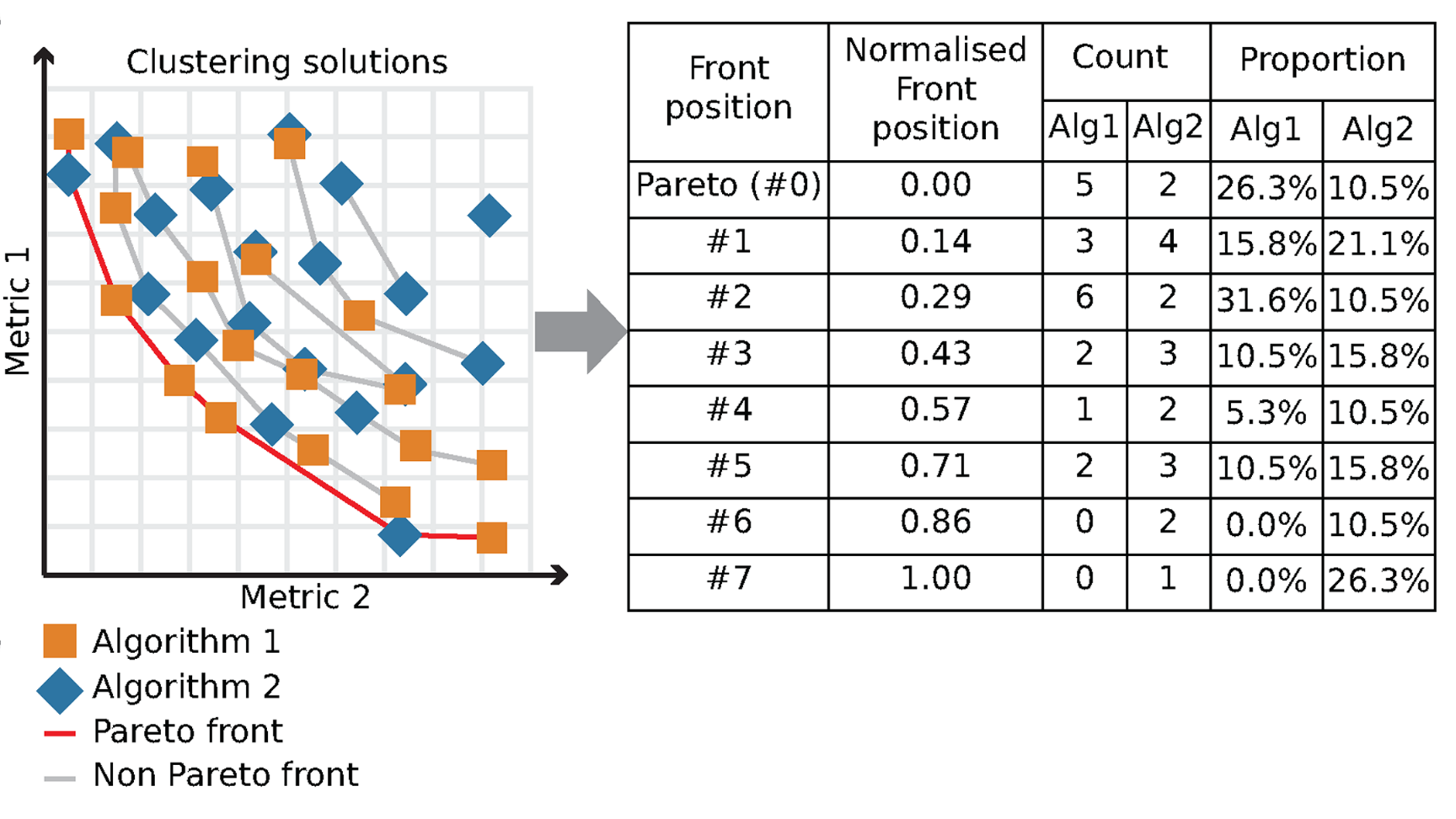
This paper developed Pareto fronts as a framework for providing an unbiased evaluation of clustering algorithms, drawing on many metrics and many datasets simultaneously. It employs ‘wisdom of crowds’ (or ‘trial by jury’) to make better decisions based on many perspectives. Critically, it is an ability to offer competitive performance on all datasets and metrics simultaneously that makes for a superior algorithm. We showed this on high-dimensional cytometry data, but the principles are transferable to any application domain.
Find the ParetoBench paper here , and the GitHub repository here.